- Data flow is a system concern
- Step 1: The user interaction
- Step 2: Authentication and identity
- Step 3: Middleware as the gatekeeper
- Step 4: Business logic and system coordination
- Step 5: Data storage and retrieval
- Step 6: The return path to the user
- Why controlled data flow matters
- A real-world context: complex and sensitive products
- Key takeaway
- Looking at your own data flows?
How Data Flows Through Modern Applications (From User to Database)
- Data flow is a system concern
- Step 1: The user interaction
- Step 2: Authentication and identity
- Step 3: Middleware as the gatekeeper
- Step 4: Business logic and system coordination
- Step 5: Data storage and retrieval
- Step 6: The return path to the user
- Why controlled data flow matters
- A real-world context: complex and sensitive products
- Key takeaway
- Looking at your own data flows?
When users interact with an application, it often feels simple:
click a button, submit a form, view some data.
Behind the scenes, however, data moves through multiple layers, systems, and decisions before it ever reaches a database, and again on its way back to the user.
Understanding this flow is key to building applications that are secure, reliable, and scalable.
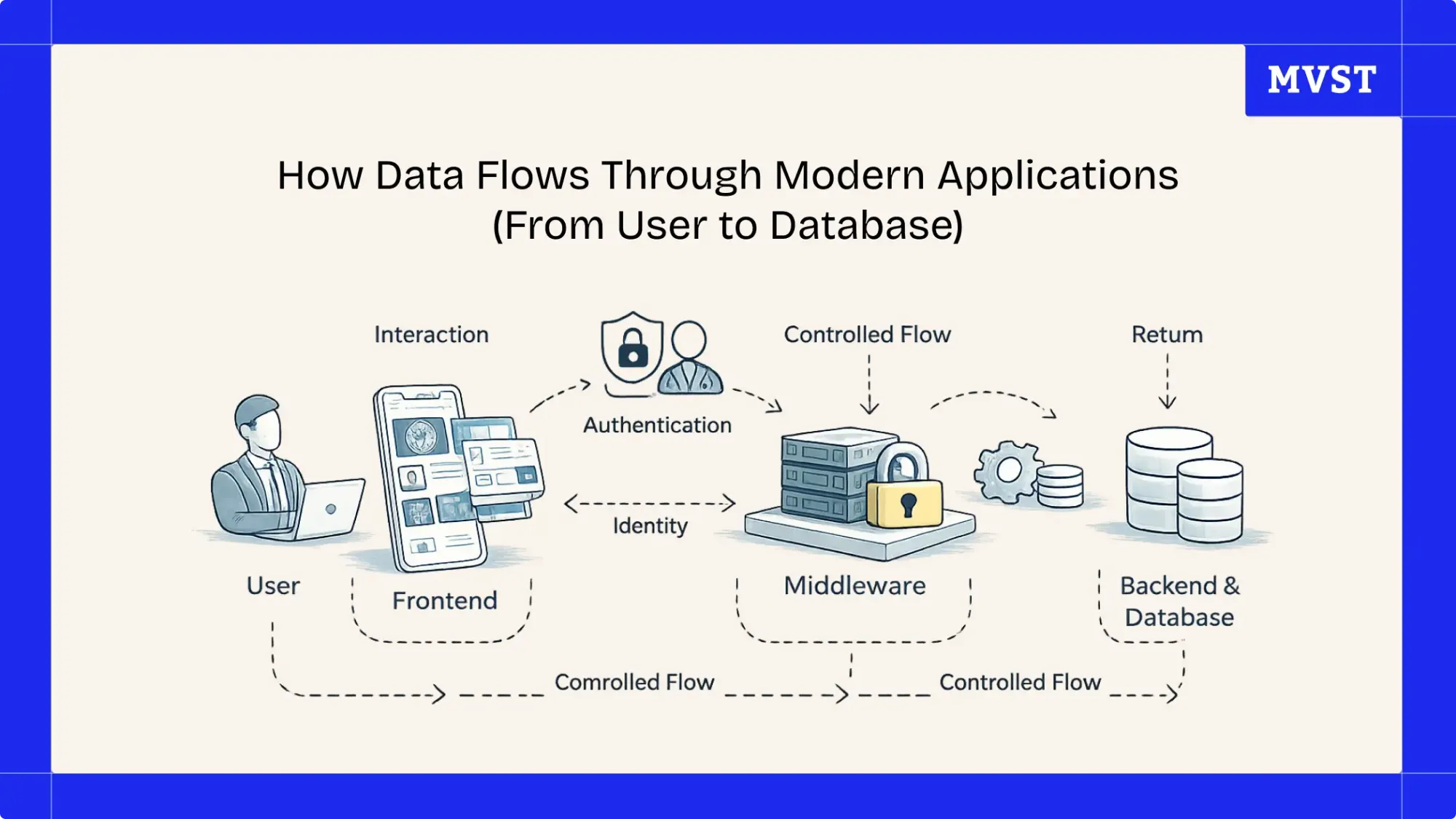
Data flow is a system concern
In modern applications, data does not travel directly from the user interface to the database.
Instead, it passes through a series of layers, each with a specific responsibility:
- Identity and authentication
- Access control and permissions
- Business logic and validation
- Integration with other systems
- Storage and retrieval
Each step exists to reduce risk, manage complexity, and enforce responsibility.
Step 1: The user interaction
Every data flow begins with a user action:
- Submitting a form
- Requesting information
- Uploading data
- Triggering a process
At this stage, the frontend’s role is limited:
- Collect input
- Display information
- Send requests
The frontend should never decide what data is valid, allowed, or safe to store.
Step 2: Authentication and identity
Before any meaningful data processing happens, the system needs to know who is making the request.
Authentication establishes:
- The identity of the user
- Whether the request is coming from a trusted source
- The context of the session
This information becomes part of the request and travels with it through the system.
Without a verified identity, data flow should stop here.
Step 3: Middleware as the gatekeeper
Once a request enters the system, middleware becomes the central decision-making layer.
Middleware is responsible for:
- Validating incoming data
- Enforcing access rules
- Applying business logic
- Filtering or transforming data
- Coordinating between services
This is where most rules live.
Rather than letting data flow freely, middleware decides whether it should flow at all, and in which form.
Step 4: Business logic and system coordination
Modern applications rarely rely on a single backend or database.
Middleware often needs to:
- Combine data from multiple sources
- Trigger background processes
- Communicate with external APIs
- Apply domain-specific rules
This coordination ensures that data remains consistent and meaningful across the system.
Step 5: Data storage and retrieval
Only after passing all checks and transformations does data reach storage systems.
At this point:
- Data is stored in a structured form
- Relationships and constraints are enforced
- Access is restricted based on context
Databases are not decision-makers - they are sources of truth.
The responsibility for what gets stored lies entirely upstream.
Step 6: The return path to the user
Data flow doesn’t end at storage.
When data is sent back to the user:
- Permissions are checked again
- Sensitive fields may be removed
- Formats are adapted for the UI
The data returned to the frontend is often not the same data that exists in the database.
This asymmetry is intentional.
Why controlled data flow matters
Uncontrolled data flow can lead to:
- Security vulnerabilities
- Accidental data exposure
- Inconsistent behavior
- Compliance violations
By clearly defining how data moves through the system, teams can:
- Reduce risk
- Improve maintainability
- Scale features safely
- Meet regulatory requirements
Data flow design is therefore a foundational architectural concern.
A real-world context: complex and sensitive products
In products dealing with sensitive information, such as preventive healthcare platforms like aeon - data flow decisions directly affect trust and responsibility.
Architecture must ensure that:
- Not every request can reach every system
- Data exposure is minimized by default
- Each layer has a clear role
In these systems, data flow is not just technical plumbing, it is a reflection of product values.
Key takeaway
Modern applications are defined by how data flows through them.
From user interaction to database storage and back, each layer:
- Adds control
- Reduces risk
- Enforces responsibility
Well-designed data flows make applications safer, more flexible, and easier to evolve over time.
Looking at your own data flows?
If you’re building a product where data moves across multiple systems, and you want to ensure those flows are clear, secure, and scalable - it’s worth examining how responsibility is distributed across your architecture.
If you’d like a second perspective on your data flow design, feel free to reach out.
BlogBits und Bytes voller digitaler Einblicke.
Praxisnahe Einblicke zu KI-Integration, Headless E-Commerce, UX/UI-Design und digitaler Produktentwicklung. Fallstudien, Implementierungsleitfäden und Expertenperspektiven vom MVST-Team in München und Barcelona.
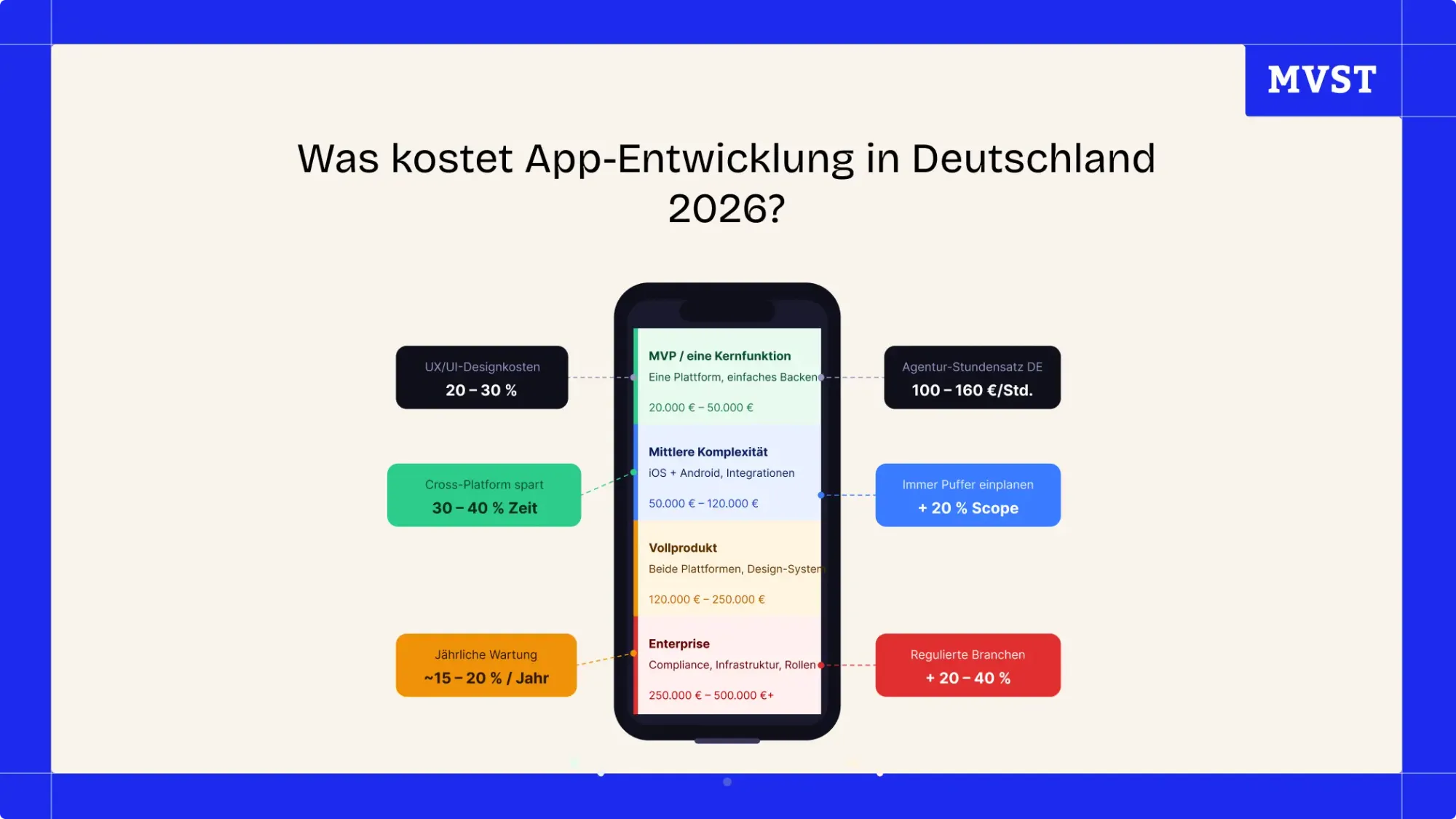
Was kostet App-Entwicklung in Deutschland 2026?
Ghida El Badri17. Juni 2026
Die besten KI-Events in Barcelona 2026
Ghida El Badri16. Juni 2026
6 KPIs, die jede Digital-Agentur tracken sollte
Ghida El Badri28. Mai 2026