- Datenflüsse sind ein Systemthema
- Schritt 1: Die Nutzerinteraktion
- Schritt 2: Authentifizierung und Identität
- Schritt 3: Middleware als Kontrollinstanz
- Schritt 4: Geschäftslogik und Systemkoordination
- Schritt 5: Speicherung und Abruf von Daten
- Schritt 6: Der Rückweg zum Nutzer
- Warum kontrollierte Datenflüsse wichtig sind
- Praxisbezug: komplexe und sensible Produkte
- Zentrale Erkenntnis
- Blick auf deine eigenen Datenflüsse?
Wie Daten durch moderne Anwendungen fließen (vom Nutzer zur Datenbank)
- Datenflüsse sind ein Systemthema
- Schritt 1: Die Nutzerinteraktion
- Schritt 2: Authentifizierung und Identität
- Schritt 3: Middleware als Kontrollinstanz
- Schritt 4: Geschäftslogik und Systemkoordination
- Schritt 5: Speicherung und Abruf von Daten
- Schritt 6: Der Rückweg zum Nutzer
- Warum kontrollierte Datenflüsse wichtig sind
- Praxisbezug: komplexe und sensible Produkte
- Zentrale Erkenntnis
- Blick auf deine eigenen Datenflüsse?
Wenn Nutzer mit einer Anwendung interagieren, fühlt sich das oft einfach an:
ein Button wird geklickt, ein Formular abgeschickt, Daten angezeigt.
Hinter den Kulissen jedoch bewegen sich Daten durch mehrere Schichten, Systeme und Entscheidungsstufen, bevor sie überhaupt eine Datenbank erreichen - und erneut auf dem Weg zurück zum Nutzer.
Dieses Zusammenspiel zu verstehen ist entscheidend, um Anwendungen zu bauen, die sicher, zuverlässig und skalierbar sind.
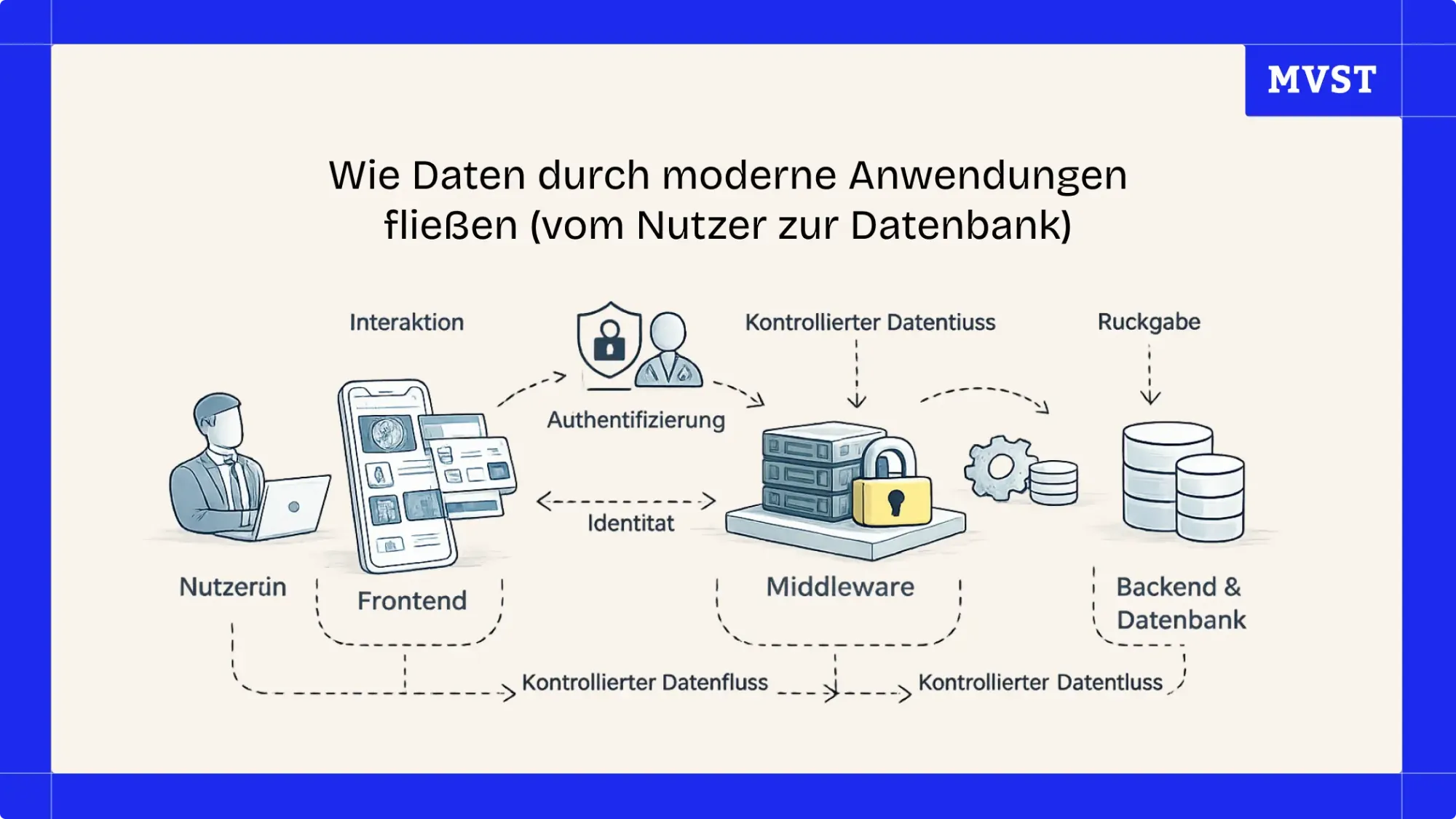
Datenflüsse sind ein Systemthema
In modernen Anwendungen wandern Daten nicht direkt von der Benutzeroberfläche in die Datenbank.
Stattdessen durchlaufen sie mehrere Schichten, die jeweils eine klar definierte Aufgabe haben:
- Identität und Authentifizierung
- Zugriffskontrolle und Berechtigungen
- Geschäftslogik und Validierung
- Integration weiterer Systeme
- Speicherung und Abruf
Jeder dieser Schritte dient dazu, Risiken zu reduzieren, Komplexität zu beherrschen und Verantwortung klar zuzuordnen.
Schritt 1: Die Nutzerinteraktion
Jeder Datenfluss beginnt mit einer Aktion des Nutzers:
- Absenden eines Formulars
- Abruf von Informationen
- Hochladen von Daten
- Auslösen eines Prozesses
In diesem Moment ist die Rolle des Frontends bewusst begrenzt:
- Eingaben erfassen
- Informationen anzeigen
- Anfragen senden
Das Frontend sollte niemals entscheiden, welche Daten gültig, erlaubt oder sicher zu speichern sind.
Schritt 2: Authentifizierung und Identität
Bevor Daten sinnvoll verarbeitet werden können, muss das System wissen, wer die Anfrage stellt.
Authentifizierung stellt fest:
- die Identität des Nutzers
- ob die Anfrage aus einer vertrauenswürdigen Quelle stammt
- den Kontext der Sitzung
Diese Informationen werden Teil der Anfrage und begleiten sie durch das gesamte System.
Ohne verifizierte Identität sollte der Datenfluss an dieser Stelle enden.
Schritt 3: Middleware als Kontrollinstanz
Sobald eine Anfrage ins System gelangt, wird die Middleware zur zentralen Entscheidungsschicht.
Sie ist verantwortlich für:
- Validierung eingehender Daten
- Durchsetzung von Zugriffsregeln
- Anwendung von Geschäftslogik
- Filtern oder Transformieren von Daten
- Koordination zwischen Services
Hier liegen die meisten Regeln.
Anstatt Daten ungehindert fließen zu lassen, entscheidet die Middleware, ob sie überhaupt fließen dürfen - und in welcher Form.
Schritt 4: Geschäftslogik und Systemkoordination
Moderne Anwendungen bestehen selten aus nur einem Backend oder einer einzelnen Datenbank.
Oft muss die Middleware:
- Daten aus mehreren Quellen zusammenführen
- Hintergrundprozesse auslösen
- mit externen APIs kommunizieren
- domänenspezifische Regeln anwenden
Diese Koordination stellt sicher, dass Daten systemweit konsistent und sinnvoll bleiben.
Schritt 5: Speicherung und Abruf von Daten
Erst nachdem alle Prüfungen und Transformationen erfolgt sind, erreichen Daten die Speichersysteme.
An diesem Punkt gilt:
- Daten werden strukturiert gespeichert
- Beziehungen und Einschränkungen werden durchgesetzt
- Zugriffe sind kontextabhängig eingeschränkt
Datenbanken treffen keine Entscheidungen - sie sind Quellen der Wahrheit.
Die Verantwortung dafür, was gespeichert wird, liegt vollständig vorgelagert im System.
Schritt 6: Der Rückweg zum Nutzer
Der Datenfluss endet nicht bei der Speicherung.
Wenn Daten an den Nutzer zurückgegeben werden:
- werden Berechtigungen erneut geprüft
- sensible Felder ggf. entfernt
- Formate für die Benutzeroberfläche angepasst
Die Daten, die im Frontend ankommen, sind häufig nicht identisch mit den Daten in der Datenbank.
Diese Asymmetrie ist beabsichtigt.
Warum kontrollierte Datenflüsse wichtig sind
Unkontrollierte Datenflüsse können zu:
- Sicherheitslücken
- unbeabsichtigter Datenoffenlegung
- inkonsistentem Verhalten
- Verstößen gegen Compliance-Vorgaben
führen.
Durch klar definierte Datenflüsse können Teams:
- Risiken reduzieren
- Wartbarkeit verbessern
- Features sicher skalieren
- regulatorische Anforderungen erfüllen
Das Design von Datenflüssen ist daher ein grundlegendes architektonisches Thema.
Praxisbezug: komplexe und sensible Produkte
In Produkten, die mit sensiblen Informationen arbeiten - etwa präventiven Gesundheitsplattformen wie aeon - beeinflussen Entscheidungen zu Datenflüssen unmittelbar Vertrauen und Verantwortung.
Die Architektur muss sicherstellen, dass:
- nicht jede Anfrage jedes System erreichen kann
- Datenexposition standardmäßig minimiert ist
- jede Schicht eine klar definierte Rolle hat
In solchen Systemen sind Datenflüsse nicht nur technische Leitungen - sie spiegeln Produktwerte wider.
Zentrale Erkenntnis
Moderne Anwendungen werden maßgeblich dadurch definiert, wie Daten durch sie fließen.
Von der Nutzerinteraktion über die Speicherung bis zurück ins Frontend sorgt jede Schicht dafür:
- Kontrolle hinzuzufügen
- Risiken zu reduzieren
- Verantwortung durchzusetzen
Gut gestaltete Datenflüsse machen Anwendungen sicherer, flexibler und langfristig besser weiterentwickelbar.
Blick auf deine eigenen Datenflüsse?
Wenn du ein Produkt entwickelst, bei dem Daten über mehrere Systeme hinweg verarbeitet werden, lohnt es sich, die Verteilung von Verantwortung in deiner Architektur genauer zu betrachten.
Wenn du dir dazu eine zweite Perspektive wünschst, melde dich gerne bei uns.
BlogBits und Bytes voller digitaler Einblicke.
Praxisnahe Einblicke zu KI-Integration, Headless E-Commerce, UX/UI-Design und digitaler Produktentwicklung. Fallstudien, Implementierungsleitfäden und Expertenperspektiven vom MVST-Team in München und Barcelona.
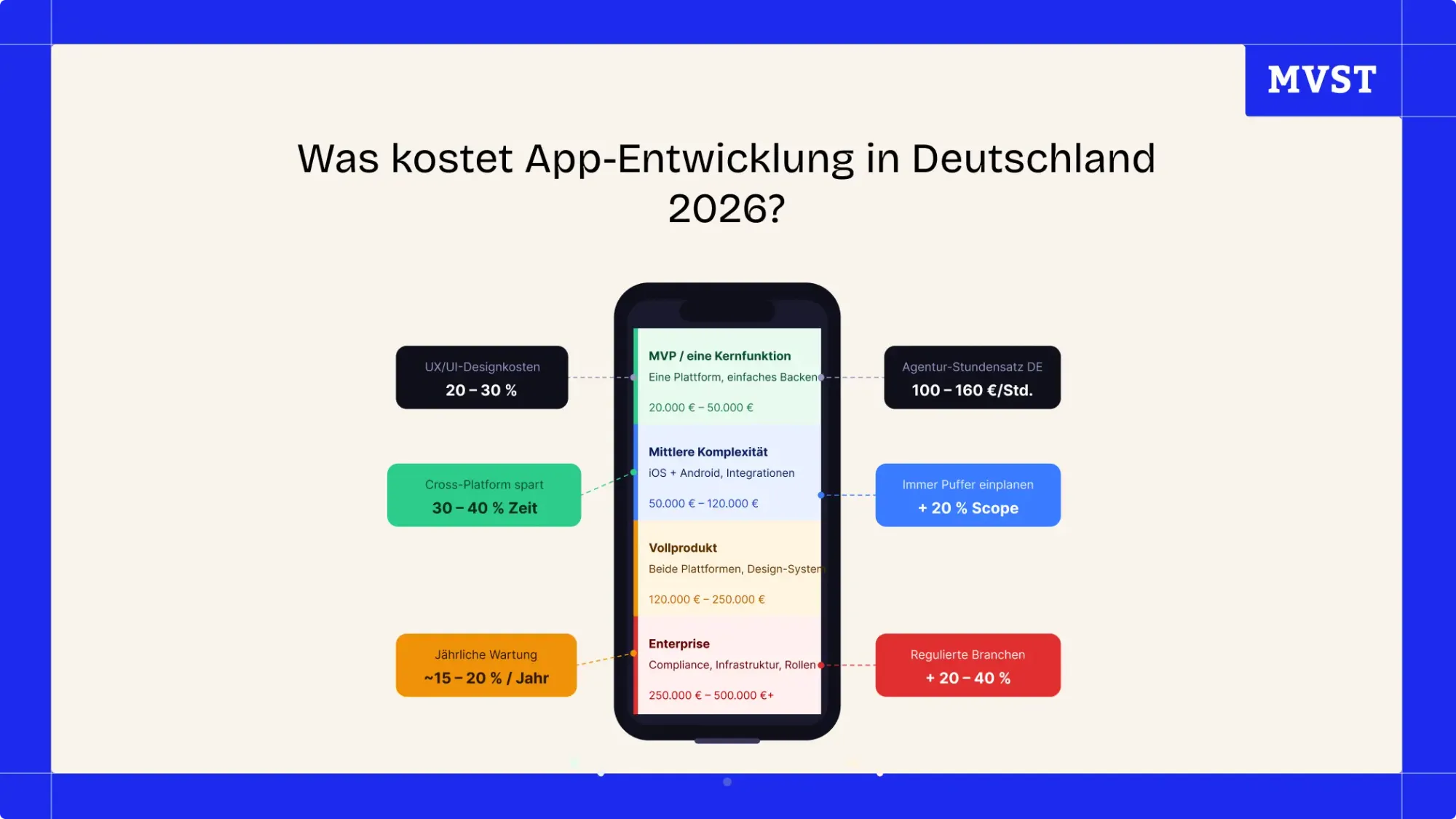
Was kostet App-Entwicklung in Deutschland 2026?
Ghida El Badri17. Juni 2026
Die besten KI-Events in Barcelona 2026
Ghida El Badri16. Juni 2026
6 KPIs, die jede Digital-Agentur tracken sollte
Ghida El Badri28. Mai 2026